
Qiskit Runtime Primitives#
"Primitive" とは#
Primitives は、量子計算を行うユーザー、量子アルゴリズムを実装する開発者、複雑な問題を解決し新しいアプリケーションを提供する研究者のための、基本的な構成要素です。
量子計算の観点からその意味を考える前に、 Primitive(プリミティブ) という言葉が何を意味するのかを考えてみましょう。
生物学者に「プリミティブとは何か」と尋ねると、おそらく「共通の祖先から受け継いだ性質、特性、特徴」と答えるでしょう。
数学者であれば、「有限体において、その体の乗法的要素群の生成元となる要素」と答えるかもしれません。
CADモデルの設計者なら、「複雑な幾何学的形状を構築するために使用できる、システム上で最も単純な形状」と説明するかもしれません。

これらから、分かることは何でしょうか?
これらの定義には、1つの共通点があります。それは、プリミティブとは、より複雑な要素を構成する基本的な要素であると定義していることです。
さて、一般的なコンピューティングに関して、「プリミティブ」という言葉はどういう意味になるでしょうか。ここでは、言語プリミティブについて見ていきましょう。
言語プリミティブとは、あるプログラミング言語で利用できる最も単純な不可分の要素と定義することができます。コンピューターの中のものはすべて0と1で記憶されているだけだと聞いたことがあると思います。
とはいえ、2進数をプログラミング言語の基本構成要素とすると、プログラムの扱いが本当に大変なことになります。そこで高級プログラミング言語におけるプリミティブ、ここでは特にプリミティブ・データ型について考えてみましょう。
言語によっては、一般にそれ以上分割できないデータ型があり、それを組み合わせることで、より複雑なデータ型を構築することができます。
例えばPythonでは、int、float、string、boolean はプリミティブ・データ型であり、
また、string(文字列)の配列 、名前のリスト 、10進座標系のタプル、integer(整数)の集合 のようなより複雑なデータ構造は、プリミティブ・データ型によって構築されたプリミティブではないデータ型として考えられています。
では、「関数」に関しても同じように定義できるのでしょうか?
プリミティブ関数は、先ほどの考え方から、使い方次第でより複雑で高度なプログラム要素やインタフェースを構築できる、インタフェースやコードセグメントとみなすことが出来ます。
なるほど、それが量子とどのような関係があるのですか?
言語プリミティブの例で説明したように、正確には(技術的には)2進数やマシンコードがプログラムをコンパイルする際の核となる構成要素であることはわかっていますが、よりプログラムの構築を簡単にできるように「プリミティブ」というより上位の言葉を定義しているのでした。
ほとんどの場合、主要なコンパイル型言語には効率的なコンパイラ処理が備わっていると期待されており、それによって私たちが使用するシステムに適した最適な実行処理が実現されています。だからこそ、私たちはその言語が提供する基本的な構文や機能を使ってプログラムを作ることができるのです。
では、量子についての質問です:量子計算のルーチンやワークフローに同様の構造を定義する方法はあるのでしょうか?
Qiskit Runtime Primitives#
Qiskit では Qiskit Runtime は、クラウドQPUを効率的に使うために、コンテナ技術を用いた新しい実行モデルを導入し、これにより、従来よりも低遅延で効率的な量子処理が可能になりました。
さらに、 Qiskit Runtime Primitives という新しいプログラミングインターフェースによって、スケーラブルで柔軟な開発がしやすくなりました。
Sampler と Estimator#
量子計算のための Primitives を定義するために、 Qiskit は2つの案を提供しています。
量子計算の基本的な構成要素は複数存在するため、今後、さらに追加される予定です。ここでは、2つの基本的な Primitives を定義しましょう。
量子コンピューターが古典コンピューターと異なる点は、出力に非古典的な確率分布を生成できることで、この点が重要です。そのため、同じ回路を複数回実行することで、確率分布として有用な情報を得ることができます。
確率分布から得られる2つの有用な情報、a)サンプリング、b)期待値の推定、に基づいて Sampler と Estimator という2つの Primitives を定義しました。
Samplerは、その名の通り、量子回路の出力からサンプリングして、擬似的な確率分布を推定します。出力からサンプリングすることで、量子回路の擬確率分布全体を推定することができます。この機能は、回路設計の際に回路全体の分布データを扱う場合に特に有効です。
つまり、ユーザーからの回路を入力とし、エラー緩和された擬確率を出力するプログラムです。これにより、ユーザーはエラー緩和を用いたショット測定結果をより正確に評価することができ、破壊的干渉の文脈で複数の関連するデータポイントの可能性をより効率的に評価することができるようになります。
要するに、回路を実行させたときに得られるおなじみの counts の出力と非常によく似ていますが、 Sampler は、エラー緩和ルーチンの結果として擬確率分布の出力を得ることができます。
簡単に言えば、より広い範囲の情報データを自由に使えるようになったのです。
擬確率分布から得られる情報は,真の確率分布の尤度を調べたり,サンプリングのオーバーヘッドと引き換えに不偏の期待値ポイントを計算したりするのに,より関連性があると思われます。これらの分布はある意味で真の確率論と同じように振る舞いますが、異なるのは、元の理論の制約がいくつか緩和されていることです。その1つが、「負の」確率を表す負のデータポイントが存在する可能性です(ただし、集合的に和が1になることはあります)。また、このデータから、使用状況に基づいて真の確率分布を推定することもできます。(例:グローバー探索、QSVMルーチン、スタビライザー計算、最適化ルーチン)
Smaplerは出力全体に対する完全な分布を与えますが、特定の結果に興味がある場合もあるでしょう。そこで、Estimator を見てみましょう!
Estimatorは、基本的に注目する演算子の期待値を計算し出力します。
回路とオブザーバブルを取り込み、与えられたパラメータに対する期待値と分散を効率的に評価するプログラム・インターフェースです。この Primitive により、多くのアルゴリズムで必要とされる量子演算子の期待値の計算を効率的に行うことができます。
ある問題に対して最終的な解を求めることに興味があり、カウントの完全な分布を調べる必要がない人は、Estimator の方が便利だと感じるでしょう。このルーチンは、 near-term の量子アルゴリズムに役立つものです。 Estimator は回路だけでなく、分子の電子構造、最適化問題のコスト関数などオブザーバブルの期待値を計算します。
Qiskit Runtimeを使う理由#
では、なぜ Primitive という新しいプログラミングパラダイムにこだわるのでしょうか?
答えは Qiskit Runtime サービスとのインターフェースと、その上に構築された強力なサービス・フレームワークを活用して効率的な量子計算を実現するためです。
先ほどはプログラムにおいて、最適化されたワークフローを実現するためにコンパイラーを前提として、より高度な開発を可能にする言語プリミティブを定義しましたが、 Qiskit Runtime は以下のような効果が期待されます。
効率 : バックエンド用に設計された反復処理ワークロードのための高度に最適化されたルーチンとオプションによって効率化されます。
レイテンシー : Sessionsフレームワークを使用したスケジューリング、ジョブの優先順位付け、共有キャッシュにより、投入されたルーチンのレイテンシーを低減し、結果を迅速に提供します。
一貫性 : 既存のプリミティブモデルを補完する新しい機能を追加し、サービス全体の複雑なルーチンの上に構築する一貫したプログラミングモデルです。
カスタマイズ性 : コンテキストとジョブのパラメーターに基づいて回路をカスタマイズし、反復ルーチンをマネージします。
エラーの軽減と抑制 : 情報の質を高めるために、シンプルな抽象化されたインターフェースでエラー軽減・抑制のための最先端の研究成果を取り入れます。
Qiskit Runtime サービスでは、 Primitive を使うことでこれらをすぐに享受できます。さっそく試してみましょう!
このノートブックでは、 Sessions フレームワークの下 Sampler と Estimator を使用する基本的な方法と、現在利用可能なエラー緩和の手法を紹介します。
import qiskit
qiskit.__version__
'1.4.2'
# instance = #<WRITE YOUR INSTANCE HERE>
# token = #<WRITE YOUR API TOKEN HERE>
# instance = #<WRITE YOUR INSTANCE HERE>
# token = #<WRITE YOUR API TOKEN HERE>
##### ライブラリーの導入
import time
import numpy as np
from qiskit import *
from qiskit.circuit import Parameter
from qiskit.quantum_info import Statevector, Pauli, SparsePauliOp
from qiskit.circuit.library import RealAmplitudes
from qiskit_aer import AerSimulator
import matplotlib.pyplot as plt
import matplotlib.ticker as tck
from qiskit.visualization import plot_histogram
Qiskit Runtime を使ってみる#
Qiskit Runtimeを使い始めることにします。
ローカルシステムで実行している場合、Qiskit Runtime パッケージをインストールする必要があるかもしれません:pip install qiskit-ibm-runtime でインストールできます。
ここではまずQiskitRuntimeServiceを定義してQiskit Runtimeのすべての要素を使用できるようにし、SamplerとEstimator Primitive を必要に応じて呼び出すことができるようにします。
Primitives を使ってみる#
それでは、Primitives構築の勘どころを、少しずつ押さえていきましょう。
まず、最初のPrimitivesはSampler primitiveです。ベルンシュタイン・ヴァジラニ アルゴリズムを使ってデモを行います。
Samplerその1: ベルンシュタイン・ヴァジラニのアルゴリズム#
ベルンシュタイン・ヴァジラニ アルゴリズムは、量子コンピューターを複雑な問題に適用した場合に優位性があることを示した量子アルゴリズムのうちの一つです。
秘密のビット文字列 \(s = s_1, s_2, \cdots s_n\) が与えられたとき、入力 \(x = x_1, x_2, \cdots x_n\) に対してパラメータ \(s\) を持つブラックボックス関数 \(f\) が与えられたとき、何回か \(x\) を問い合わせて秘密のビット文字列 \(s\) を推定する問題を考えます。
秘密のビット文字列を見つけるには通常関数 \(f\) を \(n\) 回呼び出す必要があります。しかし、量子コンピューターを使用すると、関数を 1 回呼び出すだけ で100%の信頼度でこの問題を解くことができます。
アルゴリズムは非常にシンプルです。
入力量子ビットを状態 \(|0\rangle^{\otimes n}\) に初期化し、出力量子ビットを \(|-\rangle\) に初期化する。
アダマールゲートを入力レジスターに適用する。
オラクルに問い合わせる。
アダマールゲートを入力レジスターに適用する。
測定する。
ベルンシュタイン・ヴァジラニのアルゴリズムは 重ね合わせと干渉の利用 のLabで詳しく触れているため、馴染みのない方はこちらを先にご覧ください。
ここでは秘密のビット文字列をパラメータに持つベルンシュタイン・ヴァジラニ関数を実装します。
ここで、上記の関数を呼び出して、定義されているベルンシュタイン・ヴァジラニ回路を構築します。
qc1 = bernstein_vazirani('111')
display(qc1.draw(output="mpl"))
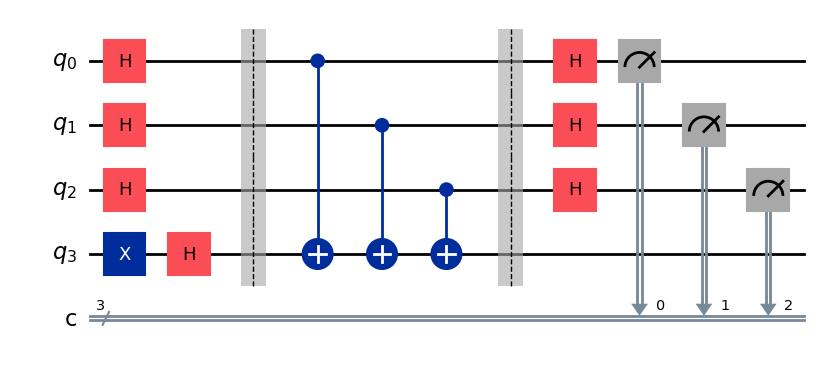
この回路を実行する前に、先ほど述べたように、1つのSamplerセッションに対して複数の回路呼び出しと実行が可能です。そのことを示すために、もう1つベルンシュタイン・ヴァジラニ回路を作ることにします。
qc2 = bernstein_vazirani('000')
display(qc2.draw(output="mpl"))
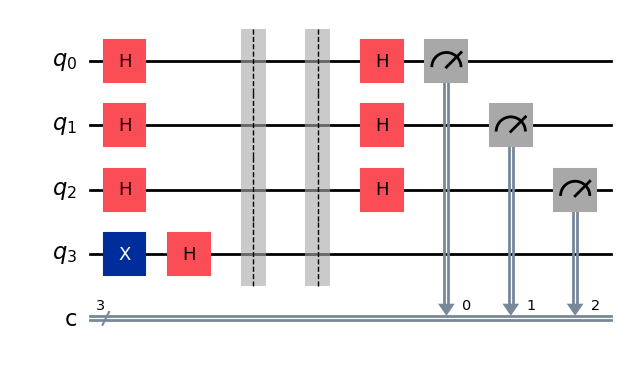
Qiskit Runtimeを使って回路を実行する#
Qiskit Runtime を使った量子回路の実行は3つのステップがあります。
使用するBackendを設定する
量子回路とオブザーバブルを実行先のバックエンドがサポートする操作に最適化(ISA: Instruction Set Architecture)する
Session (コンテキストマネージャー)を設定する
Session の中で Primitive の
SamplerまたはEstimatorをインスタンス化
step1. 使用するBackendを設定する
まず、使用するバックエンドを設定しましょう。 ここでは、クラウド上のローカル上のibmq_qasm_simulator上でルーチンを実行することにします。AerSimulator上でルーチンを実行することにします。
重要
Quantum Utilityへの移行に伴い、当時Challengeで利用していたIBM Quantum® クラウドシミュレータは廃止となりました。
シミュレータ上での実行はの下記のいずれかを利用することになります。(詳細はこちら)
qiskit_ibm_runtime.fake_providerの Fake backends: 特定のハードウェアを前提にシミュレーションしたい場合qiskit_aerのAerSimulator: より精度の高いシミュレーション結果を知りたい場合
Fake backendsを利用した例は 実際のバックエンドでVQCをテストする のLabで触れているので、ここでは AerSimulator を利用ます。
backend = AerSimulator()
step2. 量子回路とオブザーバブルを実行先のバックエンドがサポートする操作に最適化(ISA: Instruction Set Architecture)する
PrimitiveV2 のリリース以降この操作が必要となりました。このLabでは transpile のみの対応とします。
詳細はTranspiler (2024)で解説されているのでこちらをご覧ください。
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(target=backend.target, optimization_level=1)
isa_qc1 = pm.run(qc1)
isa_qc2 = pm.run(qc2)
step3. Session (コンテキストマネージャー)を設定する
Session はクラウド上で Primitives を使用する際に、セッションを安全にオープン/クローズするためのコンテキスト・マネージャーの役割を果たします。これはコンストラクターがパラメーターを取り込み、 Sampler と Estimator のメソッドがキュー内のジョブを渡すSessionキーワードを使用することで実現されます。
Sessionの構文は、シミュレータやローカルテスト時にはサポートしなくなり(文法エラーが出るわけではなく、無視される)、記述が不要となりました。
このLabではローカルテストのため、このステップは省略します。UserWarning: Session is not supported in local testing mode or when using a simulator.
step4. Session の中で Primitive の Sampler または Estimator をインスタンス化
from qiskit_ibm_runtime import SamplerV2 as Sampler, EstimatorV2 as Estimator
sampler = Sampler(backend=backend)
pub_results = sampler.run([isa_qc1, isa_qc2]).result()
[pub_result.data.c.get_int_counts() for pub_result in pub_results]
[{7: 1024}, {0: 1024}]
この結果、各回路から2つの結果が得られます。最初の回路qc1の隠れ文字列は111であり、最初の結果は7(7は2進数で111)です。この確率は1.0であり、この回路は100%確実に7を返すということです。同様に、2番目の結果は0(0は2進数で000)であり、その確率も1.0です。
Samplerその2: パラメーター化された回路#
Primitivesのメリットの1つは、パラメーター化された回路に複数のパラメーターをバインドするのが簡単になることです。
回路にパラメーターをバインドする方法の例については、 Qiskit Document をご覧ください。
ここでは制御Pゲート(制御位相ゲート)を使ったキックバックの例を紹介しましょう。
Pゲート を回転パラメーターthetaでパラメター化します。
theta = Parameter('theta')
qc = QuantumCircuit(2,1)
qc.x(1)
qc.h(0)
qc.cp(theta,0,1)
qc.h(0)
qc.measure(0,0)
qc.draw("mpl")
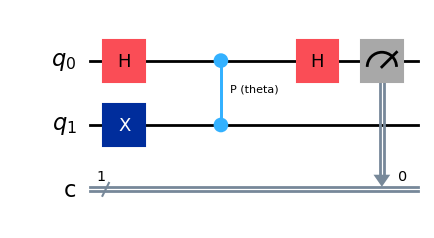
上記の回路はパラメーター化されており、固有値は測定のために量子ビット 0 に戻されます。 キックバックの度合いは、パラメーター theta によって決まります。 下のセルで、上記の回路のパラメーターをリストとして定義します。ここでのパラメーターは、\(0\) から \(2\pi\) までを50等間隔のポイントで分割したものになります。
位相制御ゲートについて、異なる位相で回路を評価してみましょう:
phases = np.linspace(0, 2*np.pi, 50) # Specify the range of parameters to look within 0 to 2pi with 50 different phases
# Phases need to be expressed as list of lists in order to work
individual_phases = [[ph] for ph in phases]
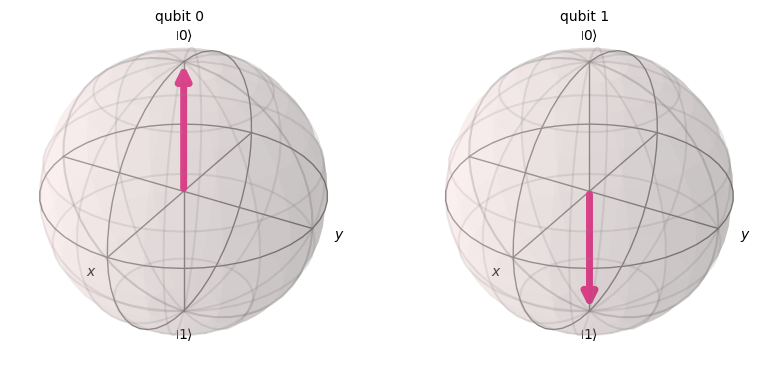
上記の回路に適用する前に、ブロッホ球を使ってどのように見えるかをイメージしてみましょう。
# help understanding of how its phase is moving
from qiskit.visualization import plot_bloch_multivector
states = []
for i in range(0, 50, 10):
temp = QuantumCircuit(2,1)
temp.x(1)
temp.h(0)
temp.cp(individual_phases[i][0],0,1)
temp.h(0)
state = Statevector(temp)
states.append(state)
plot_bloch_multivector(states[0])
plot_bloch_multivector(states[1])
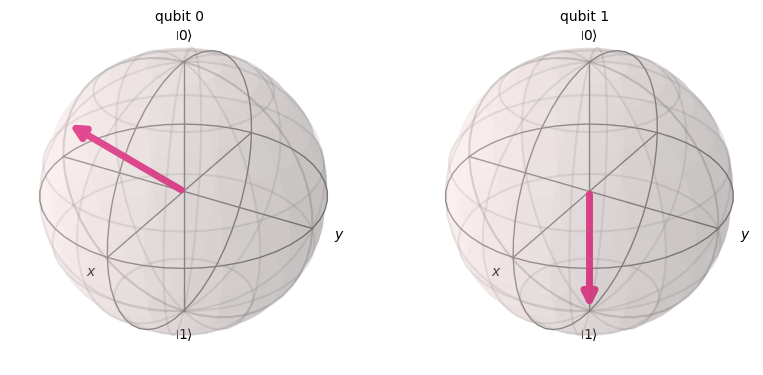
plot_bloch_multivector(states[2])
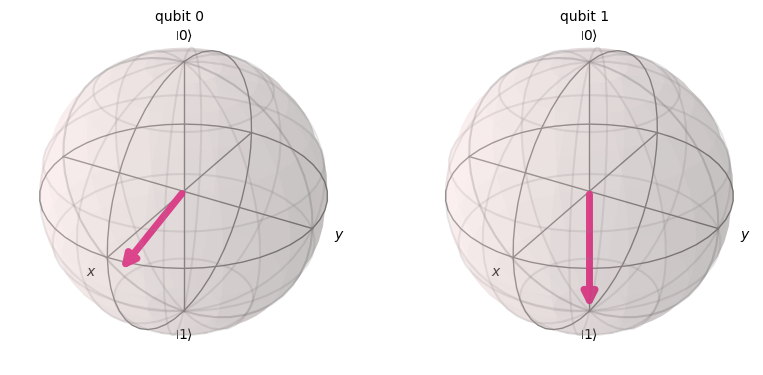
plot_bloch_multivector(states[3])
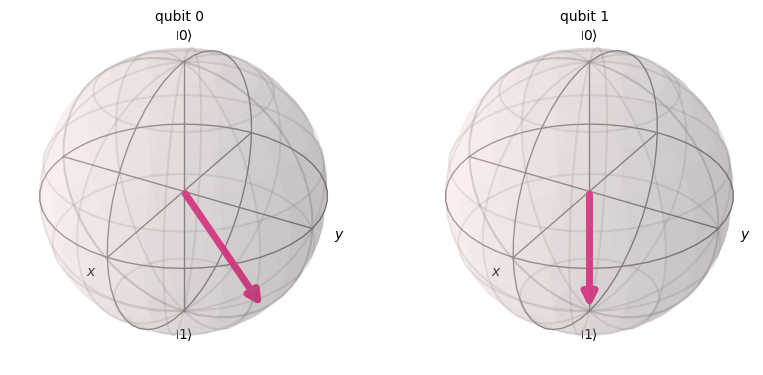
plot_bloch_multivector(states[4])
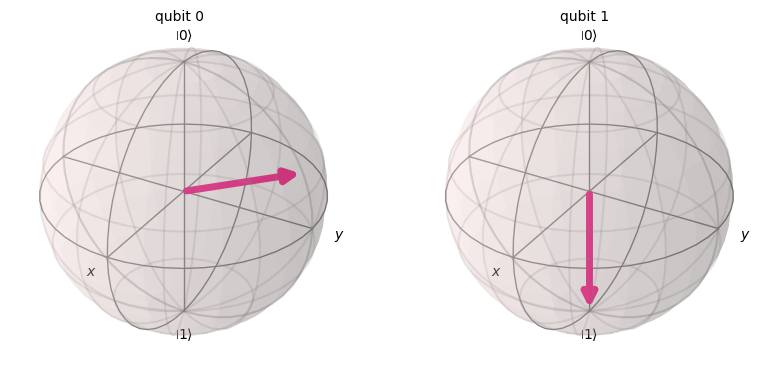
それぞれの位相で状態が変化し、Y-Z軸に沿って回転しているのがわかると思います。
パラメーターをパラメーター化された回路リストにバインドし、個々の位相 individual_phases を SamplerV2 を使用して上で作成した qc 回路にバインドします。
ここでは、再び SamplerV2 を使って、これらの回路をすべて実行し、パラメーターをバインドします。
SamplerV2の run メソッドには、以下のパラメーターがあります。
pubs: Iterable[SamplerPubLike] - PUB(Primitive Unified Blocs: 量子回路、オブザーバブル、パラメータ群、オプション) ライクなオブジェクトのイテラブル (ここでは量子回路とパラメータ群のリストと考えてください。)
shots: int - sampler pubごとにサンプリングするショットの総数
pm = generate_preset_pass_manager(target=backend.target, optimization_level=1)
isa_qc = pm.run(qc)
上のコードセルは、パラメーター化された回路を受け取り、Runtimeサービスを使ってバックエンドで実行します。このルーチンは各パラメーターを定義された回路に結びつけ、その結果得られたすべての回路を実行し、集合的な結果を得ることができます。
それでは、得られた結果と理論的に推測される結果をプロットしてみましょう。これらの回路について、1つの状態となる確率の準分布を求めます。各回路は位相パラメーターとして異なるtheta値を持つことになります。
# The probablity of being in the 1 state for each of these values
num_shots = pubs_result[0].data.c.num_shots
pubs_result_counts_list = [pub_result.data.c.get_int_counts() for pub_result in pubs_result]
prob_values = [dist.get(1, 0) / num_shots for dist in pubs_result_counts_list]
plt.plot(phases, prob_values, 'o', label='simulator')
plt.plot(phases, np.sin(phases/2,)**2, label='theory')
plt.xlabel('Phase')
plt.ylabel('Probability')
plt.legend()
<matplotlib.legend.Legend at 0x315bc9490>
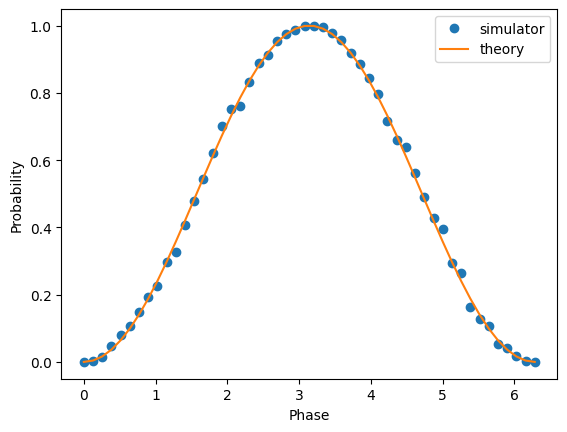
黄色い線が理論値で、青い点はバックエンドで実行したときの値です。ほぼ理論と一致していますが、シミュレータ固有のランダム性により、結果の分布のカーブには若干のずれが生じています。
ここまでは擬確率分布を見てきましたが、期待値の評価という観点からも見てみましょう。
Estimator の例#
Estimatorは、量子演算子の期待値を計算し、受け取ったものを提供します。Estimatorは、「測定操作がない」回路である必要があります。
なぜかというと、VQEのようなアルゴリズムを実行する場合、 Estimator はハミルトニアンを得るために単一量子ビットの回転をバインドするので、測定をすることができないからです。
display(qc.draw(output="mpl"))
現在の回路qcには測定があるので、remove_final_measurementsでこれを削除します。
qc_no_meas = qc.remove_final_measurements(inplace=False)
display(qc_no_meas.draw(output="mpl"))
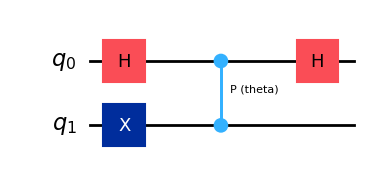
期待値を計算するために、回路にオブザーバブルを設定する必要があります。ここでは、ZZ を使います。
オブザーバブルの長さは回路の量子ビットの数と同じであることに注意してください。
ZZ = SparsePauliOp.from_list([("ZZ", 1)])
isa_ZZ = ZZ.apply_layout(qc_no_meas.layout)
期待値は以下の式で算出されます。
上の式をよく見てから、次のセルを実行することを強くお勧めします。
estimator = Estimator(backend=backend)
pubs = [(qc_no_meas, ZZ, parameter_values) for parameter_values in individual_phases]
job = estimator.run(pubs)
param_results = job.result()
exp_values = [float(param_result.data.evs) for param_result in param_results]
plt.plot(phases, exp_values, 'o', label='real')
plt.plot(phases, 2*np.sin(phases/2,)**2-1, label='theory')
plt.xlabel('Phase')
plt.ylabel('Expectation')
plt.legend()
<matplotlib.legend.Legend at 0x316308d50>
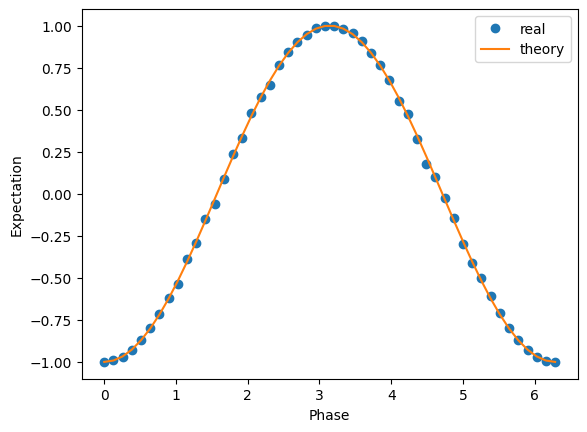
ハミルトニアンの計算#
Estimatorの面白い使い方の一つは、特にオブザーバブルに関するハミルトニアンを計算するのに使えることです。
ハミルトニアンは量子力学的な演算子であり、運動エネルギーと位置エネルギーを含む系内の全エネルギー情報を持っています。
そのためハミルトニアンの計算が必要であり、そのエネルギー値を計算できれば、自然界におけるエネルギーや、機械学習におけるコストを計算することができます。
基底状態や励起状態を見つけることができるので量子物理学、量子化学、量子機械学習と密接に関係しています。
ハミルトニアンを計算するためには、パラメーター化された回路が必要です。RealAmplitudes を使えば、ランダムなパラメーター化された回路を簡単に作ることができます。以下にコード例を示します。
ansatz = RealAmplitudes(3, reps=2) # create the circuit on 3 qubits
ansatz.decompose().draw("mpl")
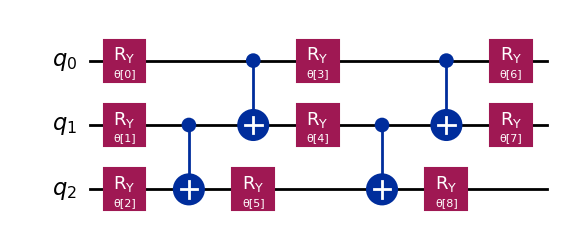
このansatzは3量子ビットの回路で、reps は2です。この場合、パラメータの総数は\(3 \times (2+1) = 9\)となります。
Exercise 3: 期待値計算の推定ルーチンを構築#
Exercise
特定の観測値に関するカスタムハミルトニアンの期待値を計算する推定ルーチンを構築します。解答は、EstimatorResult である必要があります。
\( \langle \psi_1(\theta) \lvert H_1 \lvert \psi_1(\theta)\rangle\), \( \langle \psi_2(\theta) \lvert H_2 \lvert \psi_2(\theta)\rangle\), \( \langle \psi_3(\theta) \lvert H_3 \lvert \psi_3(\theta)\rangle\)をEstimatorを使って計算します。回路は全て5量子ビットで構成されています。
RealAmplitudesを使ってランダムな回路を作ります; \(\psi_1(\theta) \)はreps = 2 、 \( \psi_2(\theta) \)はreps = 3、 \( \psi_3(\theta) \)はreps = 4です。
##### Make three random circuits using RealAmplitudes
psi1 = # build your code here
psi2 = # build your code here
psi3 = # build your code here
SparsePauliOpを使ってハミルトニアンを作ります。
\( H_1 = X_1Z_2 + 3Y_0Y_4 \)
\( H_2 = 2X_3 \)
\( H_3 = 3Y_2 + 5Z_1X_3 \)
##### Make hamiltonians using SparsePauliOp
H1 = # build your code here
H2 = # build your code here
H3 = # build your code here
numpy.linspaceを使って0から1までの theta の値を等間隔に並べたリストを作ります。なお、各回路の
repsが異なるため、パラメーターの数が異なります。
##### Make a list of evenly spaced values for theta between 0 and 1
theta1 = # build your code here
theta2 = # build your code here
theta3 = # build your code here
セル内で定義された
optionsを持つEstimatorを使って、各期待値を計算します。
##### Use the Estimator to calculate each expectation value
estimator = # build your code here
# calculate [ <psi1(theta1)|H1|psi1(theta1)>,
# <psi2(theta2)|H2|psi2(theta2)>,
# <psi3(theta3)|H3|psi3(theta3)> ]
# Note: Please keep the order
job = # build your code here
pubs_result = # build your code here
SparsePauliOpを使ってハミルトニアンを定義しています。H1の二つ目の項は以下のように示されます。
("YIIIY", 3)
左の"YIIIY"は\(Y_{0}Y_{4}\)を示し、右の3は係数を示します。
この時、右から左の順番であることやIdentity gateが含まれていることに注意してください。
また、バックエンドに渡す量子回路、オブザーバブルはISAに従っている必要があること忘れないようにしましょう。
0から1までの \(\theta\) の値を各回路のパラメータ数に合わせて分割します。 例えば、
RealAmplitudes(num_qubits=5, reps=2, insert_barriers=True)
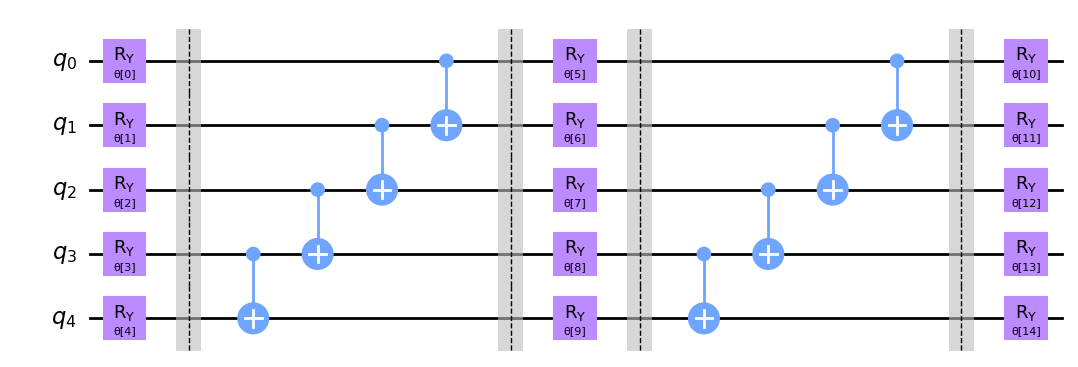 で構築された回路の場合、パラメータの数は15になります。
で構築された回路の場合、パラメータの数は15になります。
for i, pub_result in enumerate(pubs_result):
print(f"Expectation values of H_{i}: {pub_result.data.evs}")
Expectation values of H_0: 0.0068359375
Expectation values of H_1: 1.78515625
Expectation values of H_2: -0.9541015625