量子アルゴリズム: 変分量子アルゴリズム#
和訳版の講義スライドPDFはこちらです。コードは非推奨になる可能性があることに注意してください。
この実験を実行するためのおおよその QPU 時間は 9 分です (ibm_brisbane でテスト)
(このノートブックは、オープンプランで許可されている時間内に終わらない可能性があります。量子コンピューティングのリソースを賢くご利用ください。)
1. はじめに#
このチュートリアルでは、量子古典ハイブリッドアルゴリズムの概要を説明し、特に変分量子固有値ソルバー (VQE) と量子近似最適化アルゴリズム (QAOA) に焦点を当てます。これらのアルゴリズムの主な目的は、パラメーター化された量子ゲートを備えた量子回路を使って最適化の問題に取り組むことです。
量子コンピューティングの進歩にもかかわらず、現在の量子デバイスにはノイズが存在するため、深い量子回路から意味のある結果を抽出することが困難になっています。この課題を克服するために、VQEとQAOAは、量子計算を使用して比較的短い量子回路を反復的に実行し、古典計算を使用して目的となるパラメータ化された量子回路のパラメーターを最適化するハイブリッド量子古典的アプローチです。
QAOAは、さまざまなエラー緩和・抑制技術の適用により、ユーティリティー規模の問題に対する最適なソリューションを提供する可能性があります。VQEには、拡張性が低い多くのアプリケーション(量子化学など)があります。しかし、クリロフ部分空間対角化やサンプルベースの量子対角化(SQD)など、VQEを補完および拡張するための固有値関連のアプローチが数多く登場しています。VQEを理解することは、幅広い古典量子ハイブリッドアルゴリズムを理解するための重要な第一歩です。
このモジュールでは、VQEとQAOAの基本的な概念と実装について説明します。今後のチュートリアルでは、これらのアルゴリズムをスケールアップするための高度なトピックとテクニックについて説明します。
このノートブックを実行するには、環境に次のライブラリーが必要です。まだインストールしていない場合は、コメントを解除して次のセルを実行することでインストールできます。
# % pip install qiskit[visualization] qiskit-ibm-runtime
2. 簡単なハミルトニアンの最小固有値の計算#
VQEを非常に単純なケースに適用して、それがどのように機能するかを確認することから始めます。VQEでパウリ \(Z\) 行列の最小固有値を計算します。まず、いくつかの一般的なパッケージをインポートします。
import numpy as np
from qiskit.circuit import ParameterVector, QuantumCircuit
from qiskit.primitives import StatevectorEstimator, StatevectorSampler
from qiskit.quantum_info import SparsePauliOp
from scipy.optimize import minimize
はじめに、目的の演算子を定義し、行列形式で表示します。
op = SparsePauliOp("Z")
op.to_matrix()
array([[ 1.+0.j, 0.+0.j],
[ 0.+0.j, -1.+0.j]])
この固有値を古典的に取得するのは簡単なので、ここで確認のために計算します。この計算は、ユーティリティー規模に拡大するにつれて困難になる可能性があります。ここではnumpyを使用します。
# compute eigenvalues with numpy
result = np.linalg.eigh(op.to_matrix())
print("Eigenvalues:", result.eigenvalues)
Eigenvalues: [-1. 1.]
変分量子アルゴリズムを使用して固有値を取得するために、変分パラメーターを使うゲートを用いた回路を構築します。
# define a variational form
param = ParameterVector("a", 3)
qc = QuantumCircuit(1, 1)
qc.u(param[0], param[1], param[2], 0)
qc_estimator = qc.copy()
qc.measure(0, 0)
qc.draw("mpl")
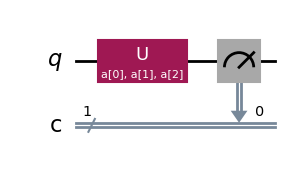
演算子の期待値( \(Z\) など)を推定したい場合は、Estimator を使用する必要があります。システムの状態を調べたい場合は、Sampler を使用します。
sampler = StatevectorSampler()
estimator = StatevectorEstimator()
Sampler を使用して、ランダムなパラメーター値 [1, 2, 3] を使用してビット文字列 0 と 1 のカウントを計算できます。
# compute counts of bitstrings with random parameter values by Sampler
result = sampler.run([(qc, [1, 2, 3])]).result()
counts = result[0].data.c.get_counts()
counts
{'0': 778, '1': 246}
Zの期待値は、\(\langle Z \rangle = p_0 - p_1\)で、確率は\(\{0:p_0, 1:p_1\}\)で計算できることがわかっています。
# compute the expectation value of Z based on the counts
(counts.get("0", 0) - counts.get("1", 0)) / sum(counts.values())
0.51953125
この回路は機能しましたが、選択されたパラメーター値は、非常に低エネルギー(または低い固有値)の状態に対応していませんでした。得られる固有値は最小値よりかなり高いです。Estimator を使用する場合も、結果は同様です。
Estimator は測定なしで量子回路を取得することに注意してください。
result = estimator.run([(qc_estimator, op, [1, 2, 3])]).result()
result[0].data.evs
array(0.54030231)
パラメーターを検索して、最も低い固有値を生成するパラメーターを見つける必要があります。 変分形式のパラメーター値を受け取り、期待値\(\langle Z \rangle\)を返す関数を作成します。
# define a cost function to look for the minimum eigenvalue of Z
def cost(x):
result = sampler.run([(qc, x)]).result()
counts = result[0].data.c.get_counts()
expval = (counts.get("0", 0) - counts.get("1", 0)) / sum(counts.values())
# the following line shows the trajectory of the optimization
print(expval, counts)
return expval
SciPyの minimize 関数を適用して、Zの最小固有値を見つけましょう。
# minimize the cost function with scipy's minimize
min_result = minimize(cost, [0, 0, 0], method="COBYLA", tol=1e-8)
min_result
1.0 {'0': 1024}
0.544921875 {'0': 791, '1': 233}
0.5703125 {'1': 220, '0': 804}
0.56640625 {'0': 802, '1': 222}
-0.439453125 {'1': 737, '0': 287}
-0.64453125 {'1': 842, '0': 182}
-0.607421875 {'1': 823, '0': 201}
0.326171875 {'0': 679, '1': 345}
-0.65625 {'1': 848, '0': 176}
-0.9921875 {'1': 1020, '0': 4}
-0.3984375 {'1': 716, '0': 308}
-0.986328125 {'1': 1017, '0': 7}
-0.986328125 {'1': 1017, '0': 7}
-0.94921875 {'0': 26, '1': 998}
-0.9375 {'1': 992, '0': 32}
-0.9765625 {'1': 1012, '0': 12}
-0.998046875 {'1': 1023, '0': 1}
-1.0 {'1': 1024}
-0.99609375 {'1': 1022, '0': 2}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-0.998046875 {'1': 1023, '0': 1}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
-1.0 {'1': 1024}
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.0
x: [ 3.158e+00 2.386e-01 -4.966e-01]
nfev: 35
maxcv: 0.0
# check counts of bitstrings with the optimal parameters
result = sampler.run([(qc, min_result.x)]).result()
result[0].data.c.get_counts()
{'1': 1024}
2.1 演習#
VQE を使用して \(Z \otimes Z\) の最小固有値を計算します。
z2 = SparsePauliOp("ZZ")
print(z2)
print(z2.to_matrix())
SparsePauliOp(['ZZ'],
coeffs=[1.+0.j])
[[ 1.+0.j 0.+0.j 0.+0.j 0.+0.j]
[ 0.+0.j -1.+0.j 0.+0.j 0.+0.j]
[ 0.+0.j 0.+0.j -1.+0.j 0.+0.j]
[ 0.+0.j 0.+0.j 0.+0.j 1.+0.j]]
# compute eigenvalues with numpy
# define a variational form
# qc = ...
# compute counts of bitstrings with a random parameter values by Sampler
# result = sampler.run(...)
# result
# compute the expectation value of ZZ based on the counts
# verify the expectation value of ZZ with Estimator
# define a cost function to look for the minimum eigenvalue of ZZ
# def cost(x):
# expval = ...
# return expval
# minimize the cost function with scipy's minimize
# min_result = minimize(cost, [...], method="COBYLA", tol=1e-8)
# min_result
# check counts of bitstrings with the optimal parameter values
# result = sampler.run(qc, min_result.x).result()
# result
演習の解答#
対象の演算子を定義し、行列形式で表示します。
z2 = SparsePauliOp("ZZ")
print(z2)
print(z2.to_matrix())
SparsePauliOp(['ZZ'],
coeffs=[1.+0.j])
[[ 1.+0.j 0.+0.j 0.+0.j 0.+0.j]
[ 0.+0.j -1.+0.j 0.+0.j 0.+0.j]
[ 0.+0.j 0.+0.j -1.+0.j 0.+0.j]
[ 0.+0.j 0.+0.j 0.+0.j 1.+0.j]]
変分量子アルゴリズムを使用して固有値を取得するために、変分パラメーターを使ったゲートを用いた回路を構築します。
# define a variational form
param = ParameterVector("a", 6)
qc = QuantumCircuit(2, 2)
qc.u(param[0], param[1], param[2], 0)
qc.u(param[3], param[4], param[5], 1)
qc_estimator = qc.copy()
qc.measure([0, 1], [0, 1])
qc.draw("mpl")
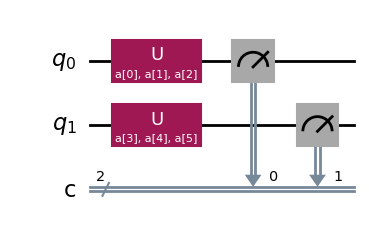
演算子の期待値(\(Z \otimes Z\)など)を推定する場合は、Estimator を使用します。システムの状態を調べたい場合は、Sampler を使用します。
sampler = StatevectorSampler()
estimator = StatevectorEstimator()
# compute counts of bitstrings with random parameter values by Sampler
result = sampler.run([(qc, [1, 2, 3, 4, 5, 6])]).result()
counts = result[0].data.c.get_counts()
counts
{'11': 212, '10': 644, '01': 33, '00': 135}
# compute the expectation value of ZZ based on the counts
(counts.get("00", 0) - counts.get("01", 0) - counts.get("10", 0) + counts.get("11", 0)) / sum(counts.values())
-0.322265625
この回路は機能しましたが、選択されたパラメーター値は、非常に低エネルギー(または低い固有値)の状態に対応していませんでした。得られる固有値は最小値よりかなり高いです。Estimator を使用する場合も、結果は同様です。
# verify the expectation value of ZZ with Estimator
result = estimator.run([(qc_estimator, z2, [1, 2, 3, 4, 5, 6])]).result()
result[0].data.evs
array(-0.35316516)
パラメーターを検索して、最も低い固有値を生成するパラメーターを見つける必要があります。
# define a cost function to look for the minimum eigenvalue of ZZ
def cost(x):
result = sampler.run([(qc, x)]).result()
counts = result[0].data.c.get_counts()
expval = (counts.get("00", 0) - counts.get("01", 0) - counts.get("10", 0) + counts.get("11", 0)) / sum(
counts.values()
)
print(expval, counts)
return expval
# minimize the cost function with scipy's minimize
min_result = minimize(cost, [0, 0, 0, 0, 0, 0], method="COBYLA", tol=1e-8)
min_result
1.0 {'00': 1024}
0.515625 {'01': 248, '00': 776}
0.568359375 {'00': 803, '01': 221}
0.484375 {'00': 760, '01': 264}
0.318359375 {'00': 622, '10': 174, '01': 175, '11': 53}
0.28515625 {'00': 607, '01': 180, '10': 186, '11': 51}
0.294921875 {'10': 191, '00': 604, '01': 170, '11': 59}
-0.09375 {'01': 440, '00': 198, '10': 120, '11': 266}
0.50390625 {'01': 192, '11': 745, '00': 25, '10': 62}
0.009765625 {'00': 313, '11': 204, '10': 247, '01': 260}
-0.0703125 {'01': 442, '11': 266, '00': 210, '10': 106}
0.146484375 {'01': 425, '11': 578, '10': 12, '00': 9}
-0.13671875 {'00': 217, '01': 467, '11': 225, '10': 115}
-0.642578125 {'11': 15, '01': 839, '00': 168, '10': 2}
-0.755859375 {'01': 893, '00': 99, '11': 26, '10': 6}
-0.7421875 {'01': 892, '11': 131, '00': 1}
-0.810546875 {'01': 927, '00': 91, '11': 6}
-0.822265625 {'01': 933, '00': 18, '11': 73}
-0.314453125 {'11': 278, '01': 638, '10': 35, '00': 73}
-0.80078125 {'01': 919, '11': 62, '00': 40, '10': 3}
-0.861328125 {'01': 952, '11': 27, '00': 44, '10': 1}
-0.923828125 {'01': 985, '11': 39}
-0.537109375 {'01': 780, '11': 217, '10': 7, '00': 20}
-0.775390625 {'11': 85, '01': 905, '00': 30, '10': 4}
-0.880859375 {'00': 58, '01': 962, '10': 1, '11': 3}
-0.888671875 {'01': 967, '11': 57}
-0.923828125 {'01': 985, '11': 39}
-0.896484375 {'01': 971, '11': 38, '00': 15}
-0.90234375 {'01': 974, '11': 49, '00': 1}
-0.9140625 {'01': 980, '11': 43, '00': 1}
-0.880859375 {'01': 963, '11': 60, '00': 1}
-0.9375 {'01': 992, '11': 32}
-0.97265625 {'01': 1010, '11': 14}
-0.994140625 {'01': 1021, '00': 1, '11': 2}
-0.98828125 {'01': 1018, '00': 6}
-0.99609375 {'01': 1022, '11': 2}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-0.99609375 {'01': 1022, '11': 1, '00': 1}
-0.99609375 {'01': 1022, '00': 1, '11': 1}
-0.982421875 {'01': 1015, '00': 9}
-0.990234375 {'01': 1019, '00': 4, '11': 1}
-0.9921875 {'01': 1020, '00': 4}
-0.994140625 {'01': 1021, '00': 3}
-0.98828125 {'01': 1018, '00': 6}
-0.994140625 {'01': 1021, '00': 3}
-0.99609375 {'01': 1022, '00': 2}
-0.994140625 {'01': 1021, '00': 3}
-0.99609375 {'01': 1022, '00': 2}
-0.9921875 {'01': 1020, '00': 4}
-0.9921875 {'01': 1020, '00': 4}
-0.994140625 {'01': 1021, '00': 3}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.990234375 {'01': 1019, '00': 5}
-0.994140625 {'01': 1021, '00': 3}
-0.9921875 {'01': 1020, '00': 4}
-0.998046875 {'01': 1023, '00': 1}
-0.994140625 {'01': 1021, '00': 3}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.990234375 {'01': 1019, '00': 5}
-0.986328125 {'01': 1017, '00': 7}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.9921875 {'01': 1020, '00': 4}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-0.994140625 {'01': 1021, '00': 3}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.98828125 {'01': 1018, '00': 6}
-0.9921875 {'01': 1020, '00': 4}
-0.998046875 {'01': 1023, '00': 1}
-0.9921875 {'01': 1020, '00': 4}
-0.98828125 {'01': 1018, '00': 6}
-0.9921875 {'01': 1020, '00': 4}
-0.990234375 {'01': 1019, '00': 5}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-1.0 {'01': 1024}
-0.998046875 {'01': 1023, '00': 1}
-0.994140625 {'01': 1021, '00': 3}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.99609375 {'01': 1022, '00': 2}
-1.0 {'01': 1024}
-0.9921875 {'01': 1020, '00': 4}
-0.99609375 {'01': 1022, '00': 2}
-0.9921875 {'01': 1020, '00': 4}
-0.998046875 {'01': 1023, '00': 1}
-0.984375 {'01': 1016, '00': 8}
-0.998046875 {'01': 1023, '00': 1}
-0.986328125 {'01': 1017, '00': 7}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-0.998046875 {'01': 1023, '00': 1}
-0.998046875 {'01': 1023, '00': 1}
-0.990234375 {'01': 1019, '00': 5}
-0.9921875 {'01': 1020, '00': 3, '11': 1}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-1.0 {'01': 1024}
-0.982421875 {'01': 1015, '00': 9}
-0.99609375 {'01': 1022, '00': 2}
-0.99609375 {'01': 1022, '00': 2}
-0.9921875 {'01': 1020, '00': 4}
-0.994140625 {'01': 1021, '00': 3}
-0.9921875 {'01': 1020, '00': 4}
-0.9921875 {'01': 1020, '00': 4}
-0.99609375 {'01': 1022, '00': 2}
-0.994140625 {'01': 1021, '00': 3}
-0.98828125 {'01': 1018, '00': 6}
-0.990234375 {'01': 1019, '00': 5}
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.0
x: [ 3.039e+00 -1.782e+00 2.364e+00 5.995e-03 2.273e+00
-1.037e+00]
nfev: 123
maxcv: 0.0
We obtained an eigenvalue extremely close to the minimum given to us from numpy.
# check counts of bitstrings with the optimal parameters
result = sampler.run([(qc, min_result.x)]).result()
result[0].data.c.get_counts()
{'01': 1020, '00': 4}
3. Qiskit patternsによる量子最適化#
このハウツーでは、Qiskit patternsと量子近似最適化について学習します。Qiskit patternsは、量子コンピューティングのワークフローを実装するための直感的で反復可能な一連の手順です。

Qiskit patterns を 組合せ最適化 に適用し、ハイブリッド(量子古典)反復手法である 量子近似最適化アルゴリズム(QAOA) を使用して Max-Cut 問題を解く方法を示します。
このQAOAパートは、量子近似最適化アルゴリズム チュートリアルの「パート1:小規模QAOA」に基づいていることに注意してください。スケールアップする方法については、チュートリアルを参照してください。
3.1 (小規模) 最適化のための Qiskit patterns#
このパートでは、小規模な Max-Cut 問題で、量子コンピューターを使用して最適化問題を解くために必要な手順を示します。
Max-Cut問題は、クラスタリング、ネットワーク科学、統計物理学など、さまざまな用途で解くのが難しい最適化問題(より具体的にはNP難問題)です。このチュートリアルでは、エッジで接続されたノードのグラフを検討し、カットされたエッジの数が最大化されるように、エッジを「カット」してノードを2つのセットに分割することを目的としています。

量子アルゴリズムにこの問題をマッピングする前に、まず関数 \(f(x)\) の最小化を考えることで、Max-Cut問題がどのように古典的な組合せ最適化問題になるのかを理解することができます。
ここで入力 \(x\) はベクトルで、その成分はグラフの各ノードに対応します。そして各成分を \(0\) または \(1\) のいずれかに制約します(それぞれカットに含まれるか含まれないかを表します)。ここでは例として \(n=5\) ノードのグラフを扱います。
ノードのペア \(i,j\) に対して、その対応する辺 \((i,j)\) がカットに含まれているかを示す関数を定義することができます。たとえば、関数 \(x_i + x_j - 2 x_i x_j\) は、 \(x_i\) または \(x_j\) のいずれか一方が 1 のとき(つまりその辺がカットに含まれるとき)だけ 1 となり、それ以外では 0 になります。
カットに含まれる辺の数を最大化する問題は次のように定式化できます。
これは次のような最小化問題に書き換えることができます。
このとき、\(f(x)\) の最小値は、カットが通過する辺の数が最大であるときに達成されます。ご覧のとおり、この時点ではまだ量子コンピュータに関連するものは登場していません。この問題を量子コンピュータが理解できる形に再定式化する必要があります。
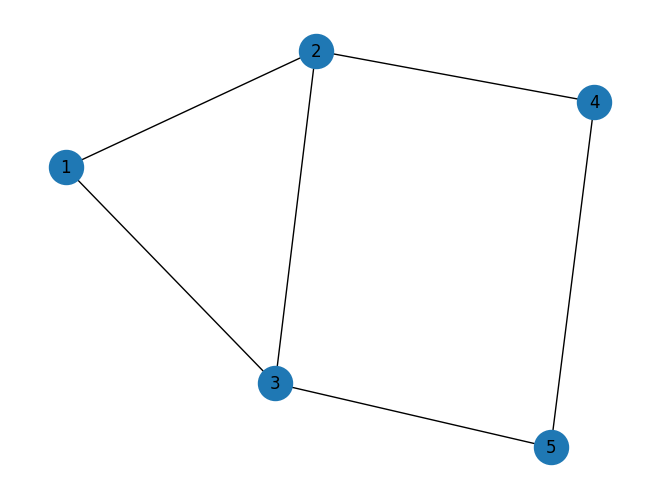
\(n=5\) ノードを持つグラフを作成して、問題を初期化します。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 5
graph = rx.PyGraph()
graph.add_nodes_from(range(1, n + 1))
edge_list = [
(0, 1, 1.0),
(0, 2, 1.0),
(1, 2, 1.0),
(1, 3, 1.0),
(2, 4, 1.0),
(3, 4, 1.0),
]
graph.add_edges_from(edge_list)
pos = rx.spring_layout(graph, seed=2)
mpl_draw(graph, node_size=600, pos=pos, with_labels=True, labels=str)
3.2 Step 1. 古典的入力を量子問題へマッピングする#
このパターンの最初のステップは、古典的な問題(グラフ)を量子 回路 や 演算子 にマッピングすることです。これを行うために、以下の3つの主要なステップを踏みます。
一連の数学的な書き換えを利用し、この問題を「制約のない二次二値最適化(Quadratic Unconstrained Binary Optimization, QUBO)」の表記を使って表す。
最適化問題を書き換えて、基底状態がコスト関数を最小化する解に対応するようなハミルトニアンにする。
量子アニーリングに似たプロセスによって、このハミルトニアンの基底状態を準備する量子回路を作成する。
注意: QAOA(量子近似最適化アルゴリズム)の手法においては、最終的に必要なのは、ハイブリッドアルゴリズムの コスト関数 を表す演算子(ハミルトニアン)と、問題の候補解に対応する量子状態を表すパラメーター化された回路(アンザッツ)です。これらの候補状態をサンプリングし、その後コスト関数を使って評価することができます。
グラフ → 最適化問題#
マッピングの最初のステップは表記の変更です。以下のように、この問題をQUBO表記で表すことができます。
ここで \(Q\) は実数の \(n \times n\) 行列、\(n\) はグラフのノードの数、\(x\) は先ほど導入した二値変数のベクトル、そして \(x^T\) は \(x\) の転置を表します。
Problem name: maxcut
Minimize
2*x_1*x_2 + 2*x_1*x_3 + 2*x_2*x_3 + 2*x_2*x_4 + 2*x_3*x_5 + 2*x_4*x_5 - 2*x_1
- 3*x_2 - 3*x_3 - 2*x_4 - 2*x_5
Subject to
No constraints
Binary variables (5)
x_1 x_2 x_3 x_4 x_5
最適化問題 → ハミルトニアン#
次に、QUBO問題を ハミルトニアン(ここでは、系のエネルギーを表す行列)として再定式化することができます:
QAOA問題からハミルトニアンへの再定式化ステップ
QAOA問題がこのように書き換えられることを示すために、まず二値変数 \(x_i\) を新しい変数 \(z_i\in\{-1,1\}\) に置き換えます:
ここでわかるように、もし \(x_i=0\) であれば \(z_i=1\) でなければなりません。\(x_i\) を \(z_i\) に置き換えて最適化問題(\(x^TQx\))に代入すると、同値な定式化が得られます。
ここで \(b_i=-\sum_{j}(Q_{ij}+Q_{ji})\) と定義し、係数や定数項 \(n^2\) を取り除くと、同じ最適化問題の二つの同値な定式化に到達します:
ここで \(b\) は \(Q\) に依存します。なお、\(z^TQz + b^Tz\) を得るために、1/4 の係数と \(n^2\) の定数項を無視しました。これらは最適化においては役割を果たさないためです。
次に、問題を量子形式にするために、変数 \(z_i\) をパウリ \(Z\) 行列に置き換えます。例えば、次のような \(2\times 2\) の行列です:
この行列を最適化問題に代入すると、次のようなハミルトニアンが得られます:
また、\(Z\) 行列は量子コンピュータの計算空間、すなわち \(2^n \times 2^n\) のヒルベルト空間に埋め込まれていることに注意してください。したがって \(Z_i Z_j\) のような項は、\(2^n \times 2^n\) のヒルベルト空間におけるテンソル積 \(Z_i \otimes Z_j\) として理解する必要があります。たとえば、5つの決定変数を持つ問題において \(Z_1Z_3\) という項は、\(I \otimes Z_3 \otimes I \otimes Z_1 \otimes I\) を意味します。ここで \(I\) は \(2 \times 2\) の単位行列です。
このハミルトニアンは コスト関数ハミルトニアン と呼ばれます。その基底状態が コスト関数 \(f(x)\) を最小化する解 に対応するという性質を持ちます。したがって、最適化問題を解くには、量子コンピュータ上で \(H_C\) の基底状態(あるいはそれと高い重なりを持つ状態)を準備する必要があります。そして、この状態からサンプリングすることで、高い確率で \(\min f(x)\) の解を得ることができます。
def build_max_cut_operator(graph: rx.PyGraph) -> tuple[SparsePauliOp, float]:
sp_list = []
constant = 0
for s, t in graph.edge_list():
w = graph.get_edge_data(s, t)
sp_list.append(("ZZ", [s, t], w / 2))
constant -= 1 / 2
return SparsePauliOp.from_sparse_list(sp_list, num_qubits=graph.num_nodes()), constant
cost_hamiltonian, constant = build_max_cut_operator(graph)
print("Cost Function Hamiltonian:", cost_hamiltonian)
print("Constant:", constant)
Cost Function Hamiltonian: SparsePauliOp(['IIIZZ', 'IIZIZ', 'IIZZI', 'IZIZI', 'ZIZII', 'ZZIII'],
coeffs=[0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j])
Constant: -3.0
ハミルトニアン → 量子回路#
ハミルトニアン \(H_C\) には、問題の量子版の定義が含まれています。ここから、量子コンピュータから「良い解」を サンプリング するのに役立つ量子回路を作ることができます。QAOAは量子アニーリングに着想を得ており、量子回路の中で演算子を交互に適用する層を重ねていきます。
基本的なアイデアは、既知の系の基底状態(上記の \(H^{\otimes n}|0\rangle\))から始め、目的とするコスト演算子の基底状態へと系を導いていくというものです。これは、角度 \(\gamma_1, \dots, \gamma_p\) および \(\beta_1, \dots, \beta_p\) をパラメータとして持つ演算子 \( \exp\{-i\gamma_k H_C\}, \quad \exp\{-i\beta_k H_m\}\) を適用することによって行われます。
生成される量子回路は \(\gamma_i\) と \(\beta_i\) によって パラメーター化 されているので、これらの値をさまざまに試し、その結果得られる状態からサンプリングを行うことができます。

この場合、2つのパラメーター \(\gamma_1\) と \(\beta_1\) を含む 1層のQAOA の例を試してみます。
from qiskit.circuit.library import QAOAAnsatz
circuit = QAOAAnsatz(cost_operator=cost_hamiltonian, reps=1)
circuit.measure_all()
circuit.draw("mpl")
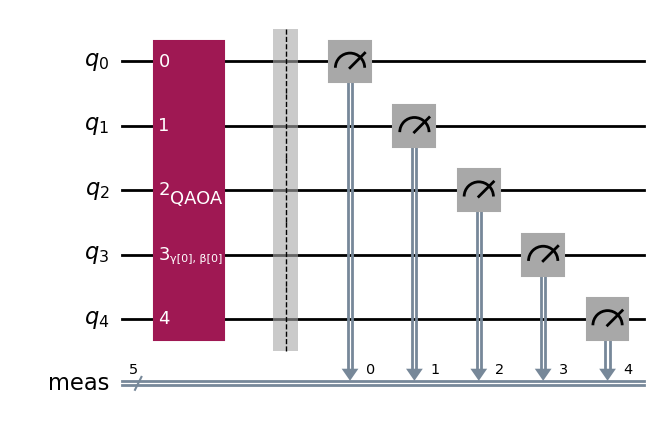
circuit.decompose(reps=3).draw("mpl", fold=-1)
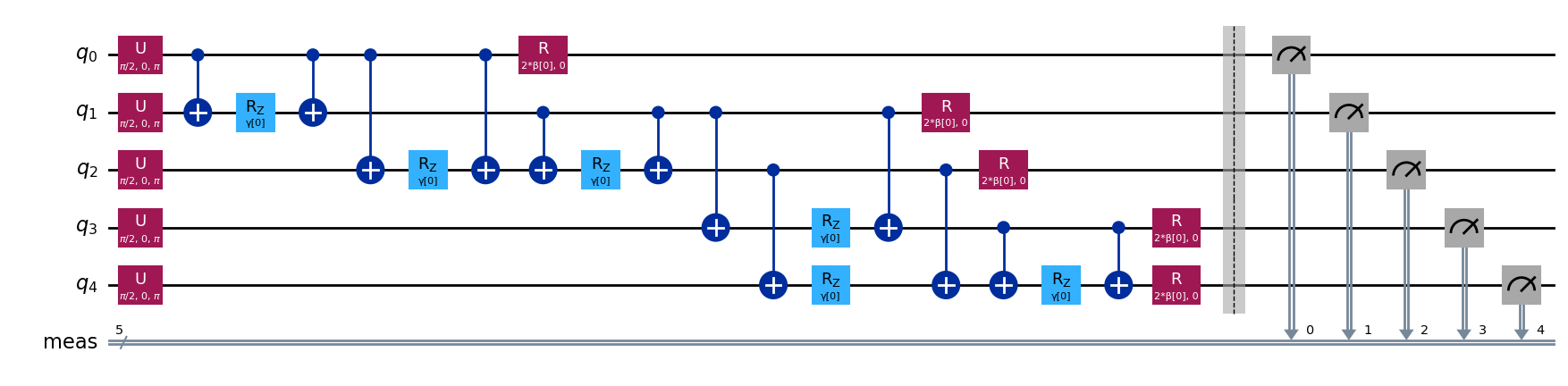
circuit.parameters
ParameterView([ParameterVectorElement(β[0]), ParameterVectorElement(γ[0])])
3.3 Step 2. 量子ハードウェア実行のための回路最適化#
上記の回路は、量子アルゴリズムを考える上で役立つ一連の抽象化を含んでいますが、そのままではハードウェア上で実行することはできません。QPU(量子プロセッサ)上で実行するためには、トランスパイル(transpilation) または 回路最適化 と呼ばれる一連の処理を経る必要があります。
Qiskitライブラリーは、幅広い回路変換に対応するさまざまな トランスパイルパス を提供しています。回路が自分の目的に合わせて 最適化 されていることを確認する必要があります。
トランスパイルには、いくつかのステップが含まれる場合があります。例えば:
回路内の量子ビット(決定変数など)をデバイス上の物理量子ビットに 初期マッピング する。
量子回路内の命令を、バックエンドが理解できるハードウェアネイティブな命令に 展開(アンローリング) する。
回路内で相互作用する量子ビットを、隣接する物理量子ビットに ルーティング する。
動的デカップリングを用いた単一量子ビットゲートの追加による エラー抑制 をする。
トランスパイルに関する詳細は、ドキュメントに記載されています。
以下のコードは、抽象的な回路を変換・最適化し、Qiskit IBM® Runtime service を使ってクラウド経由でアクセス可能な量子デバイスの1つで実行できる形式にします。
また、実機の量子コンピューターに送信する前に、「ローカルテストモード」を使ってプログラムをローカルで試すことができます。 ローカルテストモードの詳細はドキュメントをご覧ください。
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
from qiskit_ibm_runtime import QiskitRuntimeService
# Use a quantum device
service = QiskitRuntimeService()
backend = service.least_busy(min_num_qubits=127)
# You can test your programs locally with a fake backend (local testing mode)
# from qiskit_ibm_runtime.fake_provider import FakeFez
# backend = FakeFez()
print(backend)
# Create pass manager for transpilation
pm = generate_preset_pass_manager(optimization_level=3, backend=backend)
candidate_circuit = pm.run(circuit)
candidate_circuit.draw("mpl", fold=False, idle_wires=False)
<IBMBackend('ibm_fez')>

3.4 Step 3. Qiskit primitives を用いた実行#
QAOAのワークフローでは、最適なQAOAパラメータは反復的な最適化ループの中で見つけられます。このループでは回路を何度も評価し、その結果を古典的なオプティマイザ(最適化アルゴリズム)に渡して、最適な \(\beta_k\) と \(\gamma_k\) のパラメーターを求めます。 この実行ループは以下の手順で行われます:
初期パラメーターを定義する
最適化ループと、回路をサンプリングするために使う primitive を含む新しい
Sessionを生成する最適なパラメーター集合が見つかったら、回路を最終的にもう一度実行し、ポストプロセスで使用する最終的な分布を得る
初期パラメータを用いた回路の定義#
まずは任意に選んだパラメーターから始めます。
initial_gamma = np.pi
initial_beta = np.pi / 2
init_params = [initial_gamma, initial_beta]
バックエンドの定義と primitive の実行#
Qiskit Runtime primitives を使って IBM® のバックエンドとやり取りを行います。Primitive には Sampler と Estimator の2種類があり、どちらを使うかは量子コンピューター上で実行したい測定の種類に依存します。 \(H_C\) の最小化では、コスト関数の測定が \(\langle H_C \rangle\) の期待値に対応するため、Estimator を使用します。
実行#
Primitive は量子デバイス上でワークロードをスケジューリングするために、さまざまなexecution modeを提供しています。 QAOAのワークフローは、このセッションの中で反復的に実行されます。

Sampler に基づくコスト関数を SciPy の最小化ルーチンに組み込み、最適なパラメーターを見つけることができます。
def cost_func_estimator(params, ansatz, hamiltonian, estimator):
# transform the observable defined on virtual qubits to
# an observable defined on all physical qubits
isa_hamiltonian = hamiltonian.apply_layout(ansatz.layout)
pub = (ansatz, isa_hamiltonian, params)
job = estimator.run([pub])
results = job.result()[0]
cost = results.data.evs
objective_func_vals.append(cost)
return cost
from qiskit_ibm_runtime import EstimatorV2, Session
from scipy.optimize import minimize
objective_func_vals = [] # Global variable
with Session(backend=backend) as session:
estimator = EstimatorV2(session)
estimator.options.default_shots = 1000
# Set simple error suppression/mitigation options
estimator.options.dynamical_decoupling.enable = True
estimator.options.dynamical_decoupling.sequence_type = "XY4"
estimator.options.dynamical_decoupling.skip_reset_qubits = True
estimator.options.twirling.enable_gates = True
estimator.options.twirling.num_randomizations = "auto"
result = minimize(
cost_func_estimator,
init_params,
args=(candidate_circuit, cost_hamiltonian, estimator),
method="COBYLA",
tol=1e-2,
)
print(result)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.0608700803908362
x: [ 2.739e+00 6.556e-01]
nfev: 20
maxcv: 0.0
オプティマイザーはコストを下げ、回路に対してより良いパラメータを見つけることができました。
plt.figure(figsize=(12, 6))
plt.plot(objective_func_vals)
plt.xlabel("Iteration")
plt.ylabel("Cost")
plt.show()
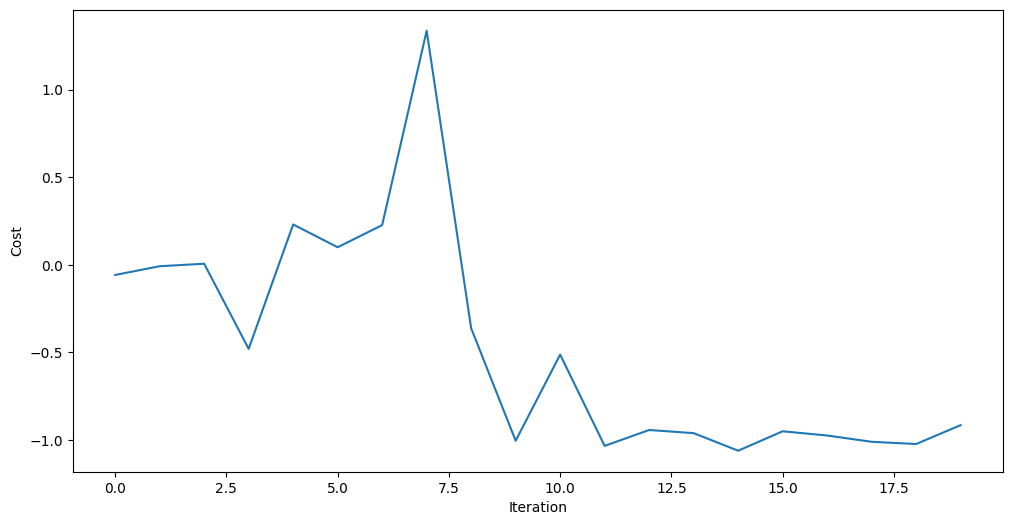
回路の最適なパラメーターが見つかったら、そのパラメーターを回路に割り当て、最適化されたパラメーターで得られる最終的な分布をサンプリングすることができます。ここでは Sampler primitive を使用します。なぜなら、この分布はビット列測定の確率分布であり、それがグラフの最適カットに対応するからです。
注: これは、量子コンピュータ内で量子状態 \(\psi\) を準備し、それを測定することを意味します。測定によって状態は単一の計算基底状態に崩壊します。例えば 010101110000... のようなビット列で、これは元の最適化問題(\(\max f(x)\) または \(\min f(x)\)、タスクに応じて)の候補解 \(x\) に対応します。
optimized_circuit = candidate_circuit.assign_parameters(result.x)
optimized_circuit.draw("mpl", fold=False, idle_wires=False)

from qiskit_ibm_runtime import SamplerV2
sampler = SamplerV2(backend)
# Set simple error suppression/mitigation options
sampler.options.dynamical_decoupling.enable = True
sampler.options.dynamical_decoupling.sequence_type = "XY4"
sampler.options.dynamical_decoupling.skip_reset_qubits = True
sampler.options.twirling.enable_gates = True
sampler.options.twirling.num_randomizations = "auto"
pub = (optimized_circuit,)
job = sampler.run([pub], shots=int(1e4))
counts_int = job.result()[0].data.meas.get_int_counts()
counts_bin = job.result()[0].data.meas.get_counts()
shots = sum(counts_int.values())
final_distribution_int = {key: val / shots for key, val in counts_int.items()}
final_distribution_bin = {key: val / shots for key, val in counts_bin.items()}
print(final_distribution_int)
{9: 0.044, 13: 0.099, 12: 0.0964, 5: 0.0145, 22: 0.0468, 28: 0.0175, 18: 0.1035, 10: 0.0273, 25: 0.0604, 1: 0.0059, 4: 0.0144, 14: 0.0435, 31: 0.0057, 2: 0.0143, 6: 0.0622, 20: 0.0284, 0: 0.008, 16: 0.0108, 30: 0.0054, 19: 0.0971, 17: 0.0412, 8: 0.0091, 26: 0.0158, 11: 0.0257, 24: 0.0065, 3: 0.0176, 29: 0.0113, 27: 0.0127, 21: 0.0262, 15: 0.0105, 7: 0.0077, 23: 0.0106}
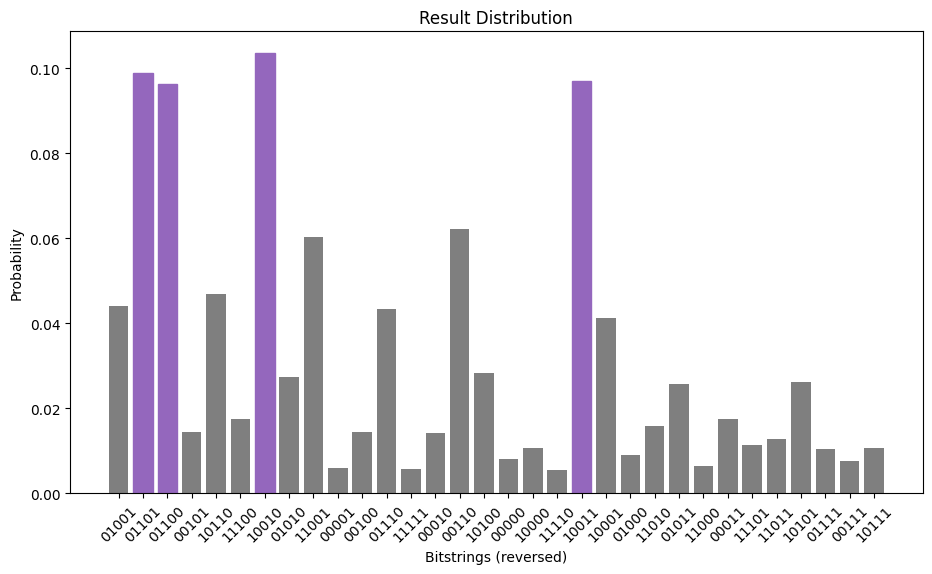
3.5 Step 4. 後処理、結果を古典的な形式で返します#
後処理ステップでは、sampling 出力を解釈して、元の問題の解を返します。この場合、最適なカットを決定するため、確率が最も高いビット文字列に関心があります。問題の対称性により、4つの可能な解が可能になり、samplingのプロセスではそのうちの1つがわずかに高い確率で返されますが、以下のプロットされた分布では、ビットストリングのうち4つが他のビットストリングよりも明らかに高い可能性が高いことがわかります。
# auxiliary functions to sample most likely bitstring
def to_bitstring(integer, num_bits):
result = np.binary_repr(integer, width=num_bits)
return [int(digit) for digit in result]
keys = list(final_distribution_int.keys())
values = list(final_distribution_int.values())
most_likely = keys[np.argmax(np.abs(values))]
most_likely_bitstring = to_bitstring(most_likely, len(graph))
most_likely_bitstring.reverse()
print("Result bitstring:", most_likely_bitstring)
Result bitstring: [0, 1, 0, 0, 1]
import matplotlib.pyplot as plt
matplotlib.rcParams.update({"font.size": 10})
final_bits = final_distribution_bin
values = np.abs(list(final_bits.values()))
top_4_values = sorted(values, reverse=True)[:4]
positions = []
for value in top_4_values:
positions.append(np.where(values == value)[0])
fig = plt.figure(figsize=(11, 6))
ax = fig.add_subplot(1, 1, 1)
plt.xticks(rotation=45)
plt.title("Result Distribution")
plt.xlabel("Bitstrings (reversed)")
plt.ylabel("Probability")
ax.bar(list(final_bits.keys()), list(final_bits.values()), color="tab:grey")
for p in positions:
ax.get_children()[p[0].item()].set_color("tab:purple")
plt.show()
ベストなカットを視覚化#
最適なビット文字列から、このカットを元のグラフで視覚化できます。
colors = ["tab:grey" if i == 0 else "tab:purple" for i in most_likely_bitstring]
mpl_draw(graph, node_size=600, pos=pos, with_labels=True, labels=str, node_color=colors)
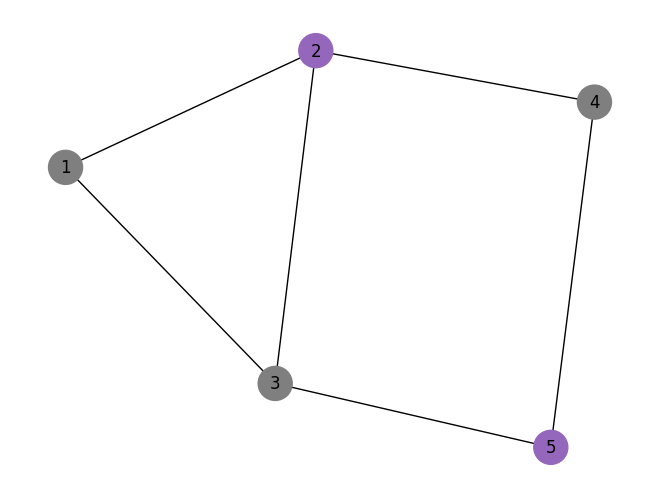
そしてカットの値を計算します。解はノイズのために必ずしも最適ではありません(最適解のカット値は5です)。
from typing import Sequence
def evaluate_sample(x: Sequence[int], graph: rx.PyGraph) -> float:
assert len(x) == len(list(graph.nodes())), "The length of x must coincide with the number of nodes in the graph."
return sum(x[u] * (1 - x[v]) + x[v] * (1 - x[u]) for u, v in list(graph.edge_list()))
cut_value = evaluate_sample(most_likely_bitstring, graph)
print("The value of the cut is:", cut_value)
The value of the cut is: 5
これで、小規模な QAOA チュートリアルは終了です。 QAOAをユーティリティスケールで適応させる方法は、量子近似最適化アルゴリズムチュートリアルの「パート2:スケールアップ!」で学習します。
# Check Qiskit version
import qiskit
qiskit.__version__
'2.1.2'
© IBM Corp., 2017-2025